
Ένας πρακτικός οδηγός με Microsoft Fabric, Kafka και MLFlow
Εισαγωγή
Στο σημερινό ψηφιακό τοπίο, η ικανότητα ανίχνευσης και απάντησης σε απειλές σε πραγματικό χρόνο δεν είναι απλώς πολυτέλεια - είναι αναγκαιότητα. Φανταστείτε να δημιουργήσετε ένα σύστημα που μπορεί να αναλύσει χιλιάδες αλληλεπιδράσεις χρηστών ανά δευτερόλεπτο, εντοπίζοντας πιθανές απόπειρες ηλεκτρονικού ψαρέματος προτού επηρεάσουν τους χρήστες σας. Αν και αυτό μπορεί να ακούγεται περίπλοκο, το Microsoft Fabric το καθιστά δυνατό, ακόμη και με δεδομένα ροής. Ας εξερευνήσουμε πώς.
Σε αυτόν τον πρακτικό οδηγό, θα σας καθοδηγήσω στη δημιουργία μιας λύσης τεχνητής νοημοσύνης από άκρο σε άκρο που επεξεργάζεται δεδομένα ροής από τον Κάφκα και χρησιμοποιεί μηχανική μάθηση για ανίχνευση απειλών σε πραγματικό χρόνο. Θα αξιοποιήσουμε την ολοκληρωμένη σουίτα εργαλείων της Microsoft Fabric για να δημιουργήσουμε, να εκπαιδεύσουμε και να αναπτύξουμε ένα μοντέλο AI που λειτουργεί άψογα με δεδομένα ροής.
Γιατί αυτό έχει σημασία
Πριν πάμε βαθύτερα στις τεχνικές λεπτομέρειες, ας διερευνήσουμε τα βασικά πλεονεκτήματα αυτής της προσέγγισης: ανίχνευση σε πραγματικό χρόνο, προληπτική προστασία και ικανότητα προσαρμογής σε αναδυόμενες απειλές.
- Επεξεργασία σε πραγματικό χρόνο: Η παραδοσιακή επεξεργασία παρτίδων δεν είναι αρκετή στο σημερινό τοπίο απειλών με γρήγορο ρυθμό. Χρειαζόμαστε άμεσες γνώσεις.
- Επεκτασιμότητα: Με τις κατανεμημένες υπολογιστικές δυνατότητες της Microsoft Fabric, η λύση μας μπορεί να χειριστεί όγκους δεδομένων εταιρικής κλίμακας.
- Ενσωμάτωση: Συνδυάζοντας την επεξεργασία δεδομένων ροής με τεχνητή νοημοσύνη, δημιουργούμε ένα σύστημα που είναι ταυτόχρονα έξυπνο και ανταποκρίνεται.
Τι θα Χτίσουμε
Δημιούργησα μια πρακτική επίδειξη που δείχνει πώς να:
- Ingest streaming data from Kafka using Microsoft Fabric’s Eventhouse
- Clean and prepare data in real-time using PySpark
- Train and evaluate an AI model for phishing detection
- Deploy the model for real-time predictions
- Store and analyze results for continuous improvement
The best part? Everything stays within the Microsoft Fabric ecosystem, making deployment and maintenance straightforward.
Azure Event Hub
Start by creating an Event Hub namespace and a new Event Hub. Azure Event Hubs have Kafka endpoints ready to start receiving Streaming Data. Create a new Shared Access Signature and utilize the Python i have created. You may adopt the Constructor to your own idea.

import uuid
import random
import time
from confluent_kafka import Producer
# Kafka configuration for Azure Event Hub
config = {
'bootstrap.servers': 'streamiot-dev1.servicebus.windows.net:9093',
'sasl.mechanisms': 'PLAIN',
'security.protocol': 'SASL_SSL',
'sasl.username': '$ConnectionString',
'sasl.password': 'Endpoint=sb://<replacewithyourendpoint>.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=xxxxxxx',
}
# Create a Kafka producer
producer = Producer(config)
# Shadow traffic generation
def generate_shadow_payload():
"""Generates a shadow traffic payload."""
subscriber_id = str(uuid.uuid4())
# Weighted choice for subscriberData
if random.choices([True, False], weights=[5, 1])[0]:
subscriber_data = f"{random.choice(['John', 'Mark', 'Alex', 'Gordon', 'Silia' 'Jane', 'Alice', 'Bob'])} {random.choice(['Doe', 'White', 'Blue', 'Green', 'Beck', 'Rogers', 'Fergs', 'Coolio', 'Hanks', 'Oliver', 'Smith', 'Brown'])}"
else:
subscriber_data = f"https://{random.choice(['example.com', 'examplez.com', 'testz.com', 'samplez.com', 'testsite.com', 'mysite.org'])}"
return {
"subscriberId": subscriber_id,
"subscriberData": subscriber_data,
}
# Delivery report callback
def delivery_report(err, msg):
"""Callback for delivery reports."""
if err is not None:
print(f"Message delivery failed: {err}")
else:
print(f"Message delivered to {msg.topic()} [partition {msg.partition()}] at offset {msg.offset()}")
# Topic configuration
topic = 'streamio-events1'
# Simulate shadow traffic generation and sending to Kafka
try:
print("Starting shadow traffic simulation. Press Ctrl+C to stop.")
while True:
# Generate payload
payload = generate_shadow_payload()
# Send payload to Kafka
producer.produce(
topic=topic,
key=str(payload["subscriberId"]),
value=str(payload),
callback=delivery_report
)
# Throttle messages (1500ms)
producer.flush() # Ensure messages are sent before throttling
time.sleep(1.5)
except KeyboardInterrupt:
print("\nSimulation stopped.")
finally:
producer.flush()
You can run this from your Workstation, an Azure Function or whatever fits your case.
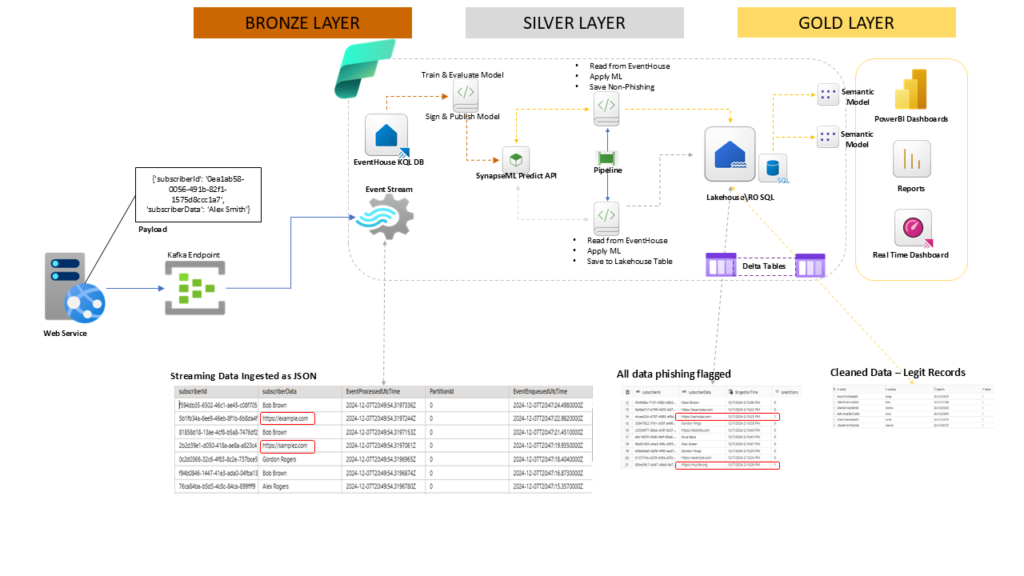
Architecture Deep Dive: The Three-Layer Approach
When building AI-powered streaming solutions, thinking in layers helps manage complexity. Let’s break down our architecture into three distinct layers:
Bronze Layer: Raw Streaming Data Ingestion
At the foundation of our solution lies the raw data ingestion layer. Here’s where our streaming story begins:
- A web service generates JSON payloads containing subscriber data
- These events flow through Kafka endpoints
- Data arrives as structured JSON with key fields like
subscriberId,subscriberData, and timestamps - Microsoft Fabric’s Eventstream captures this raw streaming data, providing a reliable foundation for our ML pipeline and stores the payloads in Eventhouse
Silver Layer: The Intelligence Hub
This is where the magic happens. Our silver layer transforms raw data into actionable insights:
- The EventHouse KQL database stores and manages our streaming data
- Our ML model, trained using PySpark’s RandomForest classifier, processes the data
- SynapseML’s Predict API enables seamless model deployment
- A dedicated pipeline applies our ML model to detect potential phishing attempts
- Results are stored in Lakehouse Delta Tables for immediate access
Gold Layer: Business Value Delivery
The final layer focuses on making our insights accessible and actionable:
- Lakehouse tables store cleaned, processed data
- Semantic models transform our predictions into business-friendly formats
- Power BI dashboards provide real-time visibility into phishing detection
- Real-time dashboards enable immediate response to potential threats
The Power of Real-Time ML for Streaming Data
What makes this architecture particularly powerful is its ability to:
- Process data in real-time as it streams in
- Apply sophisticated ML models without batch processing delays
- Provide immediate visibility into potential threats
- Scale automatically as data volumes grow
Implementing the Machine Learning Pipeline
Let’s dive into how we built and deployed our phishing detection model using Microsoft Fabric’s ML capabilities. What makes this implementation particularly interesting is how it combines traditional ML with streaming data processing.
Building the ML Foundation
First, let’s look at how we structured the training phase of our machine learning pipeline using PySpark:
Training Notebook
- Connect to Eventhouse
- Load the data
from pyspark.sql import SparkSession
# Initialize Spark session (already set up in Fabric Notebooks)
spark = SparkSession.builder.getOrCreate()
# Define connection details
kustoQuery = """
SampleData
| project subscriberId, subscriberData, ingestion_time()
""" # Replace with your desired KQL query
kustoUri = "https://<eventhousedbUri>.z9.kusto.fabric.microsoft.com" # Replace with your Kusto cluster URI
database = "Eventhouse" # Replace with your Kusto database name
# Fetch the access token for authentication
accessToken = mssparkutils.credentials.getToken(kustoUri)
# Read data from Kusto using Spark
df = spark.read \
.format("com.microsoft.kusto.spark.synapse.datasource") \
.option("accessToken", accessToken) \
.option("kustoCluster", kustoUri) \
.option("kustoDatabase", database) \
.option("kustoQuery", kustoQuery) \
.load()
# Show the loaded data
print("Loaded data:")
df.show()
- Separate and flag Phishing payload
- Load it with Spark
from pyspark.sql.functions import col, expr, when, udf
from urllib.parse import urlparse
# Define a UDF (User Defined Function) to extract the domain
def extract_domain(url):
if url.startswith('http'):
return urlparse(url).netloc
return None
# Register the UDF with Spark
extract_domain_udf = udf(extract_domain)
# Feature engineering with Spark
df = df.withColumn("is_url", col("subscriberData").startswith("http")) \
.withColumn("domain", extract_domain_udf(col("subscriberData"))) \
.withColumn("is_phishing", col("is_url"))
# Show the transformed data
df.show()
- Use Spark ML Lib to Train the model
- Evaluate the Model
from pyspark.sql.functions import col
from pyspark.ml.feature import Tokenizer, HashingTF, IDF
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
# Ensure the label column is of type double
df = df.withColumn("is_phishing", col("is_phishing").cast("double"))
# Tokenizer to break text into words
tokenizer = Tokenizer(inputCol="subscriberData", outputCol="words")
# Convert words to raw features using hashing
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=100)
# Compute the term frequency-inverse document frequency (TF-IDF)
idf = IDF(inputCol="rawFeatures", outputCol="features")
# Random Forest Classifier
rf = RandomForestClassifier(labelCol="is_phishing", featuresCol="features", numTrees=10)
# Build the ML pipeline
pipeline = Pipeline(stages=[tokenizer, hashingTF, idf, rf])
# Split the dataset into training and testing sets
train_data, test_data = df.randomSplit([0.7, 0.3], seed=42)
# Train the model
model = pipeline.fit(train_data)
# Make predictions on the test data
predictions = model.transform(test_data)
# Evaluate the model's accuracy
evaluator = MulticlassClassificationEvaluator(
labelCol="is_phishing", predictionCol="prediction", metricName="accuracy"
)
accuracy = evaluator.evaluate(predictions)
# Output the accuracy
print(f"Model Accuracy: {accuracy}")
- Add Signature to AI Model
from mlflow.models.signature import infer_signature
from pyspark.sql import Row
# Select a sample for inferring signature
sample_data = train_data.limit(10).toPandas()
# Create a Pandas DataFrame for schema inference
input_sample = sample_data[["subscriberData"]] # Input column(s)
output_sample = model.transform(train_data.limit(10)).select("prediction").toPandas()
# Infer the signature
signature = infer_signature(input_sample, output_sample)
- Run – Publish Model and Log Metric: Accuracy
import mlflow
from mlflow import spark
# Start an MLflow run
with mlflow.start_run() as run:
# Log the Spark MLlib model with the signature
mlflow.spark.log_model(
spark_model=model,
artifact_path="phishing_detector",
registered_model_name="PhishingDetector",
signature=signature # Add the inferred signature
)
# Log metrics like accuracy
mlflow.log_metric("accuracy", accuracy)
print(f"Model logged successfully under run ID: {run.info.run_id}")
Results and Impact
Our implementation achieved:
- 81.8% accuracy in phishing detection
- Sub-second prediction times for streaming data
- Scalable processing of thousands of events per second
Yes, that’s a good start ! Now let’s continue our post by explaining the deployment and operation phase of our ML solution:
From Model to Production: Automating the ML Pipeline
After training our model, the next crucial step is operationalizing it for real-time use. We’ve implemented one Pipeline with two activities that process our streaming data every 5 minutes:
All Streaming Data Notebook
# Main prediction snippet
from synapse.ml.predict import MLFlowTransformer
# Apply ML model for phishing detection
model = MLFlowTransformer(
inputCols=["subscriberData"],
outputCol="predictions",
modelName="PhishingDetector",
modelVersion=3
)
# Transform and save all predictions
df_with_predictions = model.transform(df)
df_with_predictions.write.format('delta').mode("append").save("Tables/phishing_predictions")Clean Streaming Data Notebook
# Filter for non-phishing data only
non_phishing_df = df_with_predictions.filter(col("predictions") == 0)
# Save clean data for business analysis
non_phishing_df.write.format("delta").mode("append").save("Tables/clean_data")Creating Business Value
What makes this architecture particularly powerful is the seamless transition from ML predictions to business insights:
- Delta Lake Integration:
- All predictions are stored in Delta format, ensuring ACID compliance
- Enables time travel and data versioning
- Perfect for creating semantic models
- Real-Time Processing:
- 5-minute refresh cycle ensures near real-time threat detection
- Automatic segregation of clean vs. suspicious data
- Immediate visibility into potential threats
- Business Intelligence Ready:
- Delta tables are directly compatible with semantic modeling
- Power BI can connect to these tables for live reporting
- Enables both historical analysis and real-time monitoring
The Power of Semantic Models
With our data now organized in Delta tables, we’re ready for:
- Creating dimensional models for better analysis
- Building real-time dashboards
- Generating automated reports
- Setting up alerts for security teams
Real-Time Visualization Capabilities
While Microsoft Fabric offers extensive visualization capabilities through Power BI, it’s worth highlighting one particularly powerful feature: direct KQL querying for real-time monitoring. Here’s a glimpse of how simple yet powerful this can be:
SampleData
| where EventProcessedUtcTime > ago(1m) // Fetch rows processed in the last 1 minute
| project subscriberId, subscriberData, EventProcessedUtcTimeThis simple KQL query, when integrated into a dashboard, provides near real-time visibility into your streaming data with sub-minute latency. The visualization possibilities are extensive, but that’s a topic for another day.
Conclusion: Bringing It All Together
What we’ve built here is more than just a machine learning model – it’s a complete, production-ready system that:
- Ingests and processes streaming data in real-time
- Applies sophisticated ML algorithms for threat detection
- Automatically segregates clean from suspicious data
- Provides immediate visibility into potential threats
The real power of Microsoft Fabric lies in how it seamlessly integrates these different components. From data ingestion through Eventhouse ad Lakehouse, to ML model training and deployment, to real-time monitoring – everything works together in a unified platform.
What’s Next?
While we’ve focused on phishing detection, this architecture can be adapted for various use cases:
- Fraud detection in financial transactions
- Quality control in manufacturing
- Customer behavior analysis
- Anomaly detection in IoT devices
The possibilities are endless with our imagination and creativity!
Stay tuned for the Git Repo where all the code will be shared !
Αναφορές:
- Get Started with Microsoft Fabric
- Delta Lake in Fabric
- Overview of Eventhouse
- CloudBlogger: A guide to innovative Apps with MS Fabric
