
How to create an AI Web App with Azure AI Search Vector Embeddings and Microsoft Fabric Pipelines

Εισαγωγή
Welcome, visitor! Today, we embark on an exciting journey to a Guide to innovative AI Apps using Fabric Environments. We will build an AI and Recommendations bot with cutting-edge features, helping users decide which Book is best suitable for their preferences. Our bot will handle various interactions, such as, providing customized recommendations, and engaging in chat conversations. Additionally, users can register and log in to this Azure Cloud-native AI application. Microsoft Fabric will handle, automation and AI related tasks such as:
- Load and clean the books Dataset with triggered Pipelines and Notebooks
- Transform the Dataset to JSON and making proper adjustments for Vector usability
- Load the cleaned and transformed Dataset to Azure AI Search and configuring Vector and Semantic profiles
- Create and save embeddings with Azure OpenAI to Azure AI Search
As you may already guessed our foundation lies in Microsoft Fabric, leveraging its powerful Python Notebooks, Pipelines, and Datalake toolsets. We’ll integrate these tools with a custom Identity Database and an AI Assistant. Our mission? To explore the core AI functionalities that set modern and innovative AI Apps apart—think embeddings, semantic kernel, and vectors. As we navigate Microsoft Azure’s vast offerings, we’ll build our solution from scratch..
Prerequisites for innovative AI Workshop
Apart from this guide, everything will be shared through GitHub; nevertheless we need:
Συνδρομής Azure, access to Azure OpenAI with text-embeddings ad chat-gpt deployments, Microsoft Fabric with a Pro license (trial is fine), patience and excitement!
Infrastructure
I do respect everyone’s time and i am going to point you to the Git Hub repo and the Step By Step instructions that holds the whole implementation, along with Terraform automation. We will start with the SQL query that is running within terraform. The query needs the following code:
CREATE TABLE Users (
UserId INT IDENTITY(1,1) PRIMARY KEY,
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
Username NVARCHAR(50) UNIQUE NOT NULL,
PasswordHash NVARCHAR(255) NOT NULL,
Age INT NOT NULL,
photoUrl NVARCHAR(500) NOT NULL
);
-- Genres table
CREATE TABLE Genres (
GenreId INT PRIMARY KEY IDENTITY(1,1),
GenreName NVARCHAR(50)
);
-- UsersGenres join table
CREATE TABLE UsersGenres (
UserId INT,
GenreId INT,
FOREIGN KEY (UserId) REFERENCES Users(UserId),
FOREIGN KEY (GenreId) REFERENCES Genres(GenreId)
);
ALTER DATABASE usersdb01
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)We have enabled Change Tracking in case we wan to trigger the Embeddings creation upon each change on the Database.
You can see we are using a JOIN statement to handle users and genres since the various genres selected by the users will help the assistant to make recommendations. We are also enabling Change Tracking so we can trigger updates for the Vector once a change is made. Keep in mind you need the sqlcmd installed on your Workstation !
Also you must add the OpenAI and AI Search Endpoint & API KEYs to Azure Key Vault with the names declared in the backend. You have to assign yourself the Key Vault Administrator role for that.
Vector, Embeddings & Fabric Pipelines
Yes you read it well! We are going to get a Books Dataset from Kaggle, clean it , transform it and upload it to AI Search, where we will create an index for the books. We will also create and store the embeddings using Vector Profile from AI Search. In a similar manner we will get the Users from SQL and upload them to AI Search users index, create the embeddings and save them as well. The real exciting stuff is that we will use Microsoft Fabric Pipelines and Notebooks for the books index and embeddings ! So it is important to have a Fabric Pro Trial License with the minimum capacity enabled.
Books Dataset for our innovative AI WebApp
The ultimate purpose here is to achieve automation for the creation of embeddings for both Books and Users datasets, so on the Web App we can get recommendations based on preferences but also on actual queries we set to the AI Assistant. We will get a main books dataset as Delimited Text (CSV) and transform it to JSON with correct format so it can be uploaded to Azure AI Search index, utilizing the native AI Search vector profiles and Azure OpenAI for the embeddings. The Fabric Pipelines will be triggered on schedule and we will explore other possible ways.
In Microsoft Fabric, Notebooks are an important tool as in most modern Data Platforms. The managed Spark Clusters allows us to create and execute powerful scripts in the form of Python Notebooks (PySpark), add them in a Pipeline and build solid Projects and Solutions.
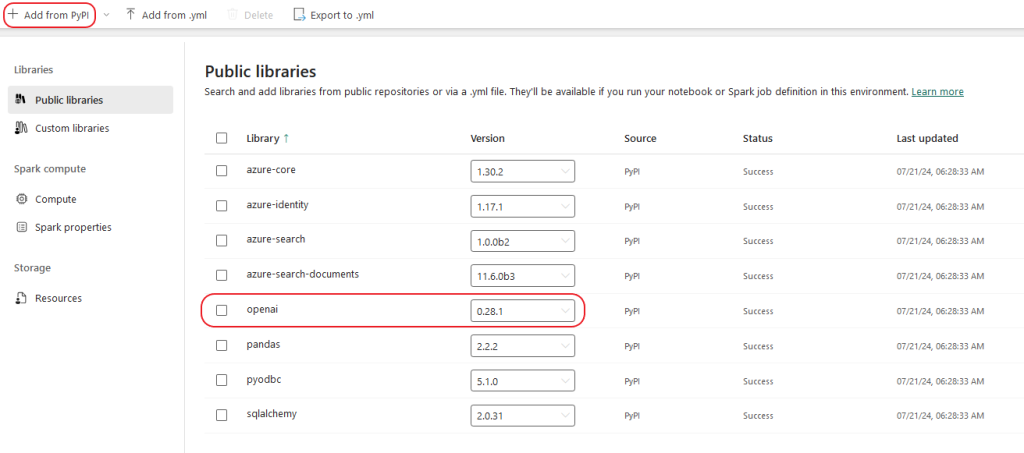
Microsoft Fabric provides the ability to pre install libraries and configure our Spark Compute within Environments, so our code will have all requirements in this managed environment. In our case we will install all required libraries and also pin the OpenAI version to pre 1.0.0 for this project. But let’s take it from the start. We need to access app.fabric.microsoft.com and create a new Workspace with a Trial Pro License. It should look like this and also has the diamond icon:
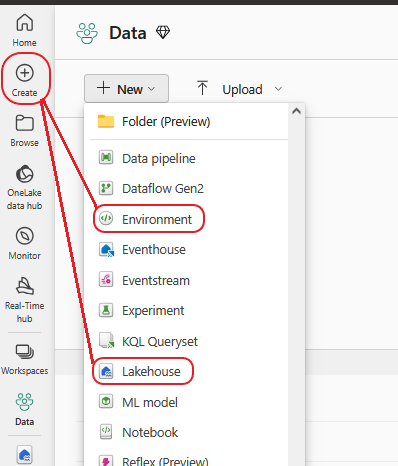
Once we have our Workspace in place we can select it and from the left menu select New and create the Environment and later a Lakehouse.
The Environment settings that worked for me are the following, you can see that we just install Public Libraries:
Since all the code will be available on GitHub i prefer to explore the next task, create the Pipeline, which will contain the Notebooks. Select your Workspace icon on the left vertical menu, find the NEW+ drop-down menu and More Options until you find the Data Pipeline. You will be presented with the familiar Synapse\Data Factory dashboard (quite similar) where we can start inserting our activities.
You have to create all Notebooks before hands just to keep everything in order. So based on the GitHub we will have 5 Notebooks ready. The Fabric API does not support yet firing pipelines, it will happen eventually, so can either schedule or work with Event Stream. The Reflex supports same Directory Azure Connections only ( We will have a look another time), but our Subscription is on another Tenant so yeah! Schedule it is !
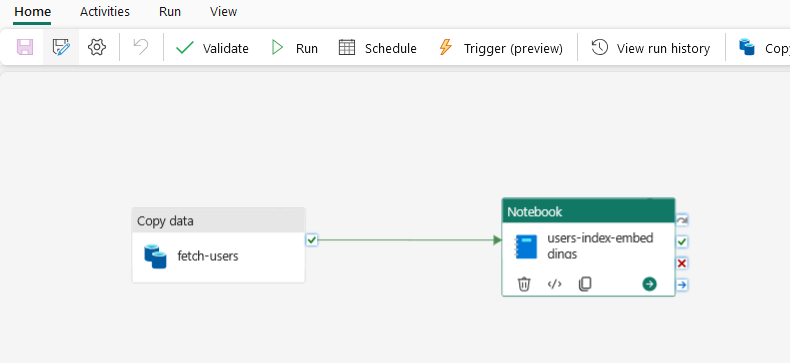
The Pipeline has the following activities:
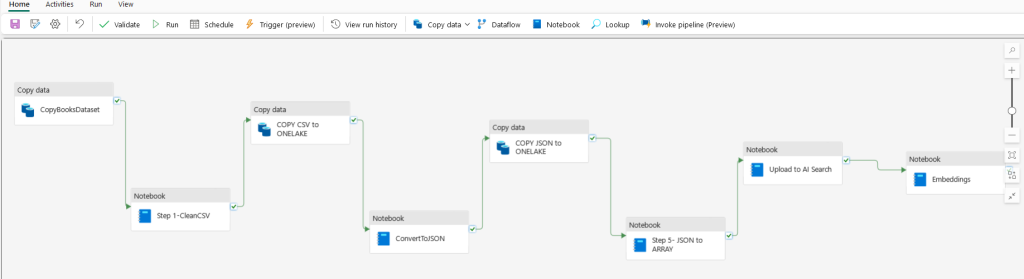
Let’s shed some light !
Once we have a Books Dataset (search Kaggle) we upload it to Azure Blob Storage. Then all yu have to do is to create a Copy Task from Fabric, to get the file fro Blob Storage into the Lakehouse, Pretty simple and straightforward.
We assume that the Dataset is stored in Blob Storage Account so we get that CSV into the Lakehouse. First Notebook is cleaning the data with Python, remove nulls, remove non-English characters and so on. Since the activity stores it as part of a Folder-like structure with non-direct access we need a task to save it on our Lakehouse.
We then transform to JSON, make the JSON a correct array set of records, again save it to Lakehouse and the last 2 Notebooks are creating the AI Search Index, uploading the JSON to AI Search, configure the AI Search with vector and semantic profiles and get all records to create embeddings from Azure OpenAI and store those back to AI Search. Due to the great number of Documents we apply rate-limit evasion (back-off) and you can be sure this will take almost 30 minutes to conclude for around 9500 records.
Users Dataset
Most of the workflow is similar for the users index and embeddings. The difference is that our users are stored and updated with new ones, in an Azure SQL Database. Since we utilize pipelines, Microsoft Fabric natively connects to Azure SQL and in fact our activity is a Copy Task but we have a query to bring SQL data.
SELECT u.UserId, u.Age, STRING_AGG(g.GenreName, ',') AS Genres
FROM Users u
JOIN UsersGenres ug ON u.UserId = ug.UserId
JOIN Genres g ON ug.GenreId = g.GenreId
GROUP BY u.UserId, u.AgeThis SQL query is selecting data from three related tables: Users, UsersGenres, and Genres. Specifically, it’s returning a list of users (based on their UserId and Age) along with a comma-separated list of all the genres associated with each user. The STRING_AGG function is used to concatenate the GenreName into a single string, separated by commas. The JOIN operations are used to link the tables together based on common fields – in this case, the UserId in the Users and UsersGenres tables, and the GenreId in the UsersGenres and Genres tables. The GROUP BY clause is grouping the results by both UserId and Age, meaning that each row in the output will represent a unique combination of these two fields.
So it is a simpler process after all, and due to the small amount of users ( i can only subscribe up to 5-6 imaginary accounts ! ), it is a quicker process.
So what have we done so far ? Well let’s break it down, shall we ?
Process of our innovative AI WebApp
- Created the main Infrastructure using Terraform – available on GitHub
- The Infra provides a Web UI where we register as users and select favorite book Genres, and can login into a Dashboard that we have access to an AI Assistant. The database used to store User’s info is Azure SQL. The Infrastructure consists also of Azure Key Vault, Azure Container Registry, Azure AI Search and Azure Web Apps. A separate Azure OpenAI is already in place.
- The backend creates a Join Table to store UserId with Genres so later it will be easier to create personalized recommendations
- We got a Books dataset with [id, Author, Title, Genres, Rating] fields and upload it to Azure Blob Storage
- We activated Trial (or just have available) license for Microsoft Fabric capacity
- We created Jupyter Notebooks to clean the source books dataset, transform it and store it as JSON
- We created a Fabric Pipeline integrating these Notebooks and new ones that create a books-index in Azure AI Search, configure it with Vector and Semantic Profiles and uploaded all JSON records in it
- The Pipeline continues with additional Notebooks that create embeddings with Azure OpenAI and store this embeddings back in Azure AI Search.
- A new Pipeline has been deployed, that gets the Users data with a query that combines the Genres information with Users from the Azure SQL Database resource and stores it as JSON
- The users Pipeline creates and configures a new users-index in Azure AI Search, configures Vector and Semantic profiles and creates embeddings, for all data, with Azure OpenAI and stores the embeddings back to the index.
Now we are left with the Backend details and maybe some minor changes for the Frontend. As you will see the GitHub repo contains all required files to create a Docker Image, push it to Container Registry and create a Web App in Azure Web Apps. Use: [ docker build -t backend . ] and tag and push: [ docker tag backend {acrname}.azurecr.io/backend:v1 ] , [ docker push {acrname}.azurecr.io/backend:v1 ]. We will be able to see our new Repo on Azure Container Registry and deploy our new Web App :
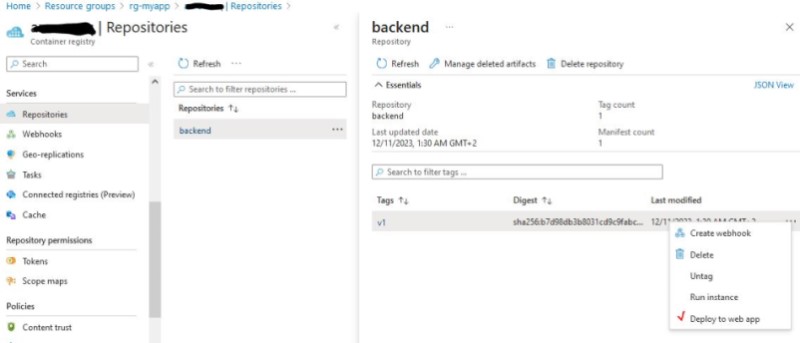
Don’t forget to add * in CORS settings for the backend Web App!
The overall Architecture is like this:
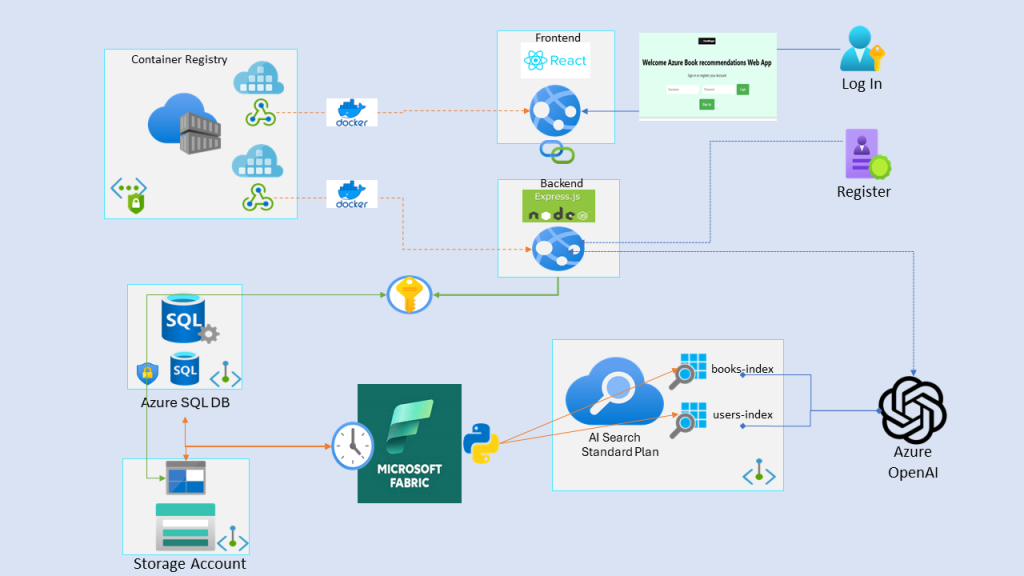
The only variable needed for the Backend Web App is the KeyVault name and the User Assigned Managed Identity ID. All access to other services (SQL, Storage Account, Ai Search, Azure OpenAI) is going through Key Vault Secrets.
Let’s have a quick look on our Backend
import dotenv from 'dotenv';
import express from 'express';
import sql from 'mssql';
import bcrypt from 'bcrypt';
import jwt from 'jsonwebtoken';
import multer from 'multer';
import azureStorage from 'azure-storage';
import getStream from 'into-stream';
import cors from 'cors';
import { SecretClient } from "@azure/keyvault-secrets";
import { DefaultAzureCredential } from "@azure/identity";
import { OpenAIClient, AzureKeyCredential } from '@azure/openai';
import { SearchClient } from '@azure/search-documents';
import bodyParser from 'body-parser';
dotenv.config();
const app = express();
app.use(cors({ origin: '*' }));
app.use((req, res, next) => {
res.setHeader('X-Content-Type-Options', 'nosniff');
next();
});
app.use(express.json());
// set up rate limiter: maximum of five requests per minute
var RateLimit = require('express-rate-limit');
var limiter = RateLimit({
windowMs: 15 * 60 * 1000, // 15 minutes
max: 100, // max 100 requests per windowMs
});
// apply rate limiter to all requests
app.use(limiter);
app.get('/:path', function(req, res) {
let path = req.params.path;
if (isValidPath(path))
res.sendFile(path);
});
const vaultName = process.env.AZURE_KEY_VAULT_NAME;
const vaultUrl = `https://${vaultName}.vault.azure.net`;
const credential = new DefaultAzureCredential({
managedIdentityClientId: process.env.MANAGED_IDENTITY_CLIENT_ID, // Use environment variable for managed identity client ID
});
const secretClient = new SecretClient(vaultUrl, credential);
async function getSecret(secretName) {
const secret = await secretClient.getSecret(secretName);
return secret.value;
}
const inMemoryStorage = multer.memoryStorage();
const uploadStrategy = multer({ storage: inMemoryStorage }).single('photo');
let sqlConfig;
let storageAccountName;
let azureStorageConnectionString;
let jwtSecret;
let searchEndpoint;
let searchApiKey;
let openaiEndpoint;
let openaiApiKey;
async function initializeApp() {
sqlConfig = {
user: await getSecret("sql-admin-username"),
password: await getSecret("sql-admin-password"),
database: await getSecret("sql-database-name"),
server: await getSecret("sql-server-name"),
options: {
encrypt: true,
trustServerCertificate: false
}
};
storageAccountName = await getSecret("storage-account-name");
azureStorageConnectionString = await getSecret("storage-account-connection-string");
jwtSecret = await getSecret("jwt-secret");
searchEndpoint = await getSecret("search-endpoint");
searchApiKey = await getSecret("search-apikey");
openaiEndpoint = await getSecret("openai-endpoint");
openaiApiKey = await getSecret("openai-apikey");
//console.log("SQL Config:", sqlConfig);
// console.log("Storage Account Name:", storageAccountName);
// console.log("Azure Storage Connection String:", azureStorageConnectionString);
// console.log("JWT Secret:", jwtSecret);
// console.log("Search Endpoint:", searchEndpoint);
// console.log("Search API Key:", searchApiKey);
// console.log("OpenAI Endpoint:", openaiEndpoint);
// console.log("OpenAI API Key:", openaiApiKey);
// Initialize OpenAI and Azure Search clients
const openaiClient = new OpenAIClient(openaiEndpoint, new AzureKeyCredential(openaiApiKey));
const userSearchClient = new SearchClient(searchEndpoint, 'users-index', new AzureKeyCredential(searchApiKey));
const bookSearchClient = new SearchClient(searchEndpoint, 'books-index', new AzureKeyCredential(searchApiKey));
// Start server
const PORT = process.env.PORT || 3001;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
}).on('error', error => {
console.error("Error initializing application:", error);
});
}
initializeApp().catch(error => {
console.error("Error initializing application:", error);
});
// Upload photo endpoint
app.post('/uploadphoto', uploadStrategy, (req, res) => {
if (!req.file) {
return res.status(400).send('No file uploaded.');
}
const blobName = `userphotos/${Date.now()}_${req.file.originalname}`;
const stream = getStream(req.file.buffer);
const streamLength = req.file.buffer.length;
const blobService = azureStorage.createBlobService(azureStorageConnectionString);
blobService.createBlockBlobFromStream('pics', blobName, stream, streamLength, err => {
if (err) {
console.error(err);
res.status(500).send('Error uploading the file');
} else {
const photoUrl = `https://${storageAccountName}.blob.core.windows.net/pics/${blobName}`;
res.status(200).send({ photoUrl });
}
});
});
// Register endpoint
app.post('/register', uploadStrategy, async (req, res) => {
const { firstName, lastName, username, password, age, emailAddress, genres } = req.body;
if (!password) {
return res.status(400).send({ message: 'Password is required' });
}
let photoUrl = '';
if (req.file) {
const blobName = `userphotos/${Date.now()}_${req.file.originalname}`;
const stream = getStream(req.file.buffer);
const streamLength = req.file.buffer.length;
const blobService = azureStorage.createBlobService(azureStorageConnectionString);
await new Promise((resolve, reject) => {
blobService.createBlockBlobFromStream('pics', blobName, stream, streamLength, err => {
if (err) {
console.error(err);
reject(err);
} else {
photoUrl = `https://${storageAccountName}.blob.core.windows.net/pics/${blobName}`;
resolve();
}
});
});
}
const hashedPassword = await bcrypt.hash(password, 10);
try {
let pool = await sql.connect(sqlConfig);
let result = await pool.request()
.input('username', sql.NVarChar, username)
.input('password', sql.NVarChar, hashedPassword)
.input('firstname', sql.NVarChar, firstName)
.input('lastname', sql.NVarChar, lastName)
.input('age', sql.Int, age)
.input('emailAddress', sql.NVarChar, emailAddress)
.input('photoUrl', sql.NVarChar, photoUrl)
.query(`
INSERT INTO Users
(Username, PasswordHash, FirstName, LastName, Age, EmailAddress, PhotoUrl)
VALUES
(@username, @password, @firstname, @lastname, @age, @emailAddress, @photoUrl);
SELECT SCOPE_IDENTITY() AS UserId;
`);
const userId = result.recordset[0].UserId;
if (genres && genres.length > 0) {
const genreNames = genres.split(','); // Assuming genres are sent as a comma-separated string
for (const genreName of genreNames) {
let genreResult = await pool.request()
.input('genreName', sql.NVarChar, genreName.trim())
.query(`
IF NOT EXISTS (SELECT 1 FROM Genres WHERE GenreName = @genreName)
BEGIN
INSERT INTO Genres (GenreName) VALUES (@genreName);
END
SELECT GenreId FROM Genres WHERE GenreName = @genreName;
`);
const genreId = genreResult.recordset[0].GenreId;
await pool.request()
.input('userId', sql.Int, userId)
.input('genreId', sql.Int, genreId)
.query('INSERT INTO UsersGenres (UserId, GenreId) VALUES (@userId, @genreId)');
}
}
res.status(201).send({ message: 'User registered successfully' });
} catch (error) {
console.error(error);
res.status(500).send({ message: 'Error registering user' });
}
});
// Login endpoint
app.post('/login', async (req, res) => {
try {
let pool = await sql.connect(sqlConfig);
let result = await pool.request()
.input('username', sql.NVarChar, req.body.username)
.query('SELECT UserId, PasswordHash FROM Users WHERE Username = @username');
if (result.recordset.length === 0) {
return res.status(401).send({ message: 'Invalid username or password' });
}
const user = result.recordset[0];
const validPassword = await bcrypt.compare(req.body.password, user.PasswordHash);
if (!validPassword) {
return res.status(401).send({ message: 'Invalid username or password' });
}
const token = jwt.sign({ UserId: user.UserId }, jwtSecret, { expiresIn: '1h' });
res.send({ token: token, UserId: user.UserId });
} catch (error) {
console.error(error);
res.status(500).send({ message: 'Error logging in' });
}
});
// Get user data endpoint
app.get('/user/:UserId', async (req, res) => {
try {
let pool = await sql.connect(sqlConfig);
let result = await pool.request()
.input('UserId', sql.Int, req.params.UserId)
.query('SELECT Username, FirstName, LastName, Age, EmailAddress, PhotoUrl FROM Users WHERE UserId = @UserId');
if (result.recordset.length === 0) {
return res.status(404).send({ message: 'User not found' });
}
const user = result.recordset[0];
res.send(user);
} catch (error) {
console.error(error);
res.status(500).send({ message: 'Error fetching user data' });
}
});
// AI Assistant endpoint for book questions and recommendations
app.post('/ai-assistant', async (req, res) => {
const { query, userId } = req.body;
console.log('Received request body:', req.body);
console.log('Extracted userId:', userId);
try {
if (!userId) {
console.error('User ID is missing from the request.');
return res.status(400).send({ message: 'User ID is required.' });
}
//console.log(`Received request for user ID: ${userId}`);
// Retrieve user data
let pool = await sql.connect(sqlConfig);
let userResult = await pool.request()
.input('UserId', sql.Int, userId)
.query('SELECT * FROM Users WHERE UserId = @UserId');
const user = userResult.recordset[0];
if (!user) {
console.error(`User with ID ${userId} not found.`);
return res.status(404).send({ message: `User with ID ${userId} not found.` });
}
console.log(`User data: ${JSON.stringify(user)}`);
if (query.toLowerCase().includes("recommendation")) {
// Fetch user genres
const userGenresResult = await pool.request()
.input('UserId', sql.Int, userId)
.query('SELECT GenreName FROM Genres g JOIN UsersGenres ug ON g.GenreId = ug.GenreId WHERE ug.UserId = @UserId');
const userGenres = userGenresResult.recordset.map(record => record.GenreName).join(' ');
//console.log(`User genres: ${userGenres}`);
// Fetch user embedding from search index
const userSearchClient = new SearchClient(searchEndpoint, 'users-index', new AzureKeyCredential(searchApiKey));
const userEmbeddingResult = await userSearchClient.getDocument(String(user.UserId));
const userEmbedding = userEmbeddingResult.Embedding;
//console.log(`User embedding result: ${JSON.stringify(userEmbeddingResult)}`);
//console.log(`User embedding: ${userEmbedding}`);
if (!userEmbedding || userEmbedding.length === 0) {
console.error('User embedding not found.');
return res.status(500).send({ message: 'User embedding not found.' });
}
// Search for recommendations
const bookSearchClient = new SearchClient(searchEndpoint, 'books-index', new AzureKeyCredential(searchApiKey));
const searchResponse = await bookSearchClient.search("*", {
vectors: [{
value: userEmbedding,
fields: ["Embedding"],
kNearestNeighborsCount: 5
}],
includeTotalCount: true,
select: ["Title", "Author"]
});
const recommendations = [];
for await (const result of searchResponse.results) {
recommendations.push({
title: result.document.Title,
author: result.document.Author,
score: result.score
});
}
// Limit recommendations to top 5
const topRecommendations = recommendations.slice(0, 5);
return res.json({ response: "Here are some personalized recommendations for you:", recommendations: topRecommendations });
} else {
// General book query
const openaiClient = new OpenAIClient(openaiEndpoint, new AzureKeyCredential(openaiApiKey));
const deploymentId = "gpt"; // Replace with your deployment ID
// Extract rating and genre from query
const ratingMatch = query.match(/rating over (\d+(\.\d+)?)/);
const genreMatch = query.match(/genre (\w+)/i);
const rating = ratingMatch ? parseFloat(ratingMatch[1]) : null;
const genre = genreMatch ? genreMatch[1] : null;
if (rating && genre) {
// Search for books with the specified genre and rating
const bookSearchClient = new SearchClient(searchEndpoint, 'books-index', new AzureKeyCredential(searchApiKey));
const searchResponse = await bookSearchClient.search("*", {
filter: `Rating gt ${rating} and Genres/any(g: g eq '${genre}')`,
top: 5,
select: ["Title", "Author", "Rating"]
});
const books = [];
for await (const result of searchResponse.results) {
books.push({
title: result.document.Title,
author: result.document.Author,
rating: result.document.Rating
});
}
const bookResponse = books.map(book => `${book.title} by ${book.author} with rating ${book.rating}`).join('\n');
return res.json({ response: `Here are 5 books with rating over ${rating} in ${genre} genre:\n${bookResponse}` });
} else {
// Handle general queries about books using OpenAI with streaming chat completions
const events = await openaiClient.streamChatCompletions(
deploymentId,
[
{ role: "system", content: "You are a helpful assistant that answers questions about books and provides personalized recommendations." },
{ role: "user", content: query }
],
{ maxTokens: 350 }
);
let aiResponse = "";
for await (const event of events) {
for (const choice of event.choices) {
aiResponse += choice.delta?.content || '';
}
}
return res.json({ response: aiResponse });
}
}
} catch (error) {
console.error('Error processing AI Assistant request:', error);
return res.status(500).send({ message: 'Error processing your request.' });
}
});As you can see apart form the registration and login endpoints we have the ai-assistant endpoint. Users are able not only to get personalized recommendations when the word “recommendations” is in the chat, but also information on Genres και ratings, again when these words are in the Chat request. Also they can chat regularly with the Assistant about books and literature!
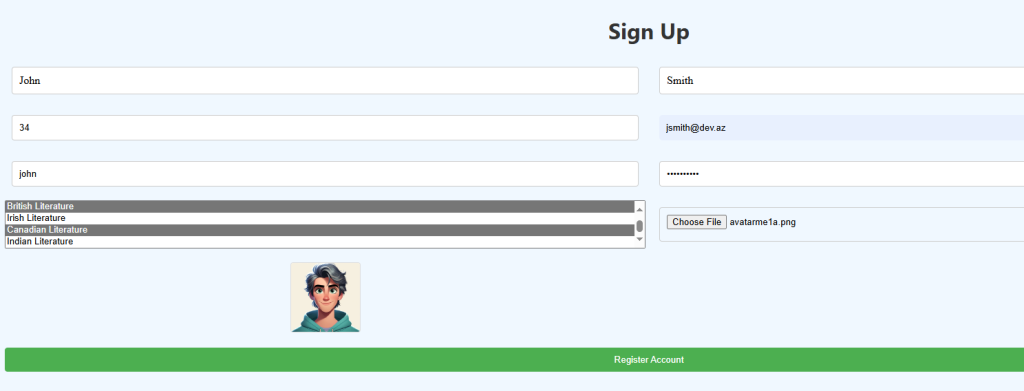

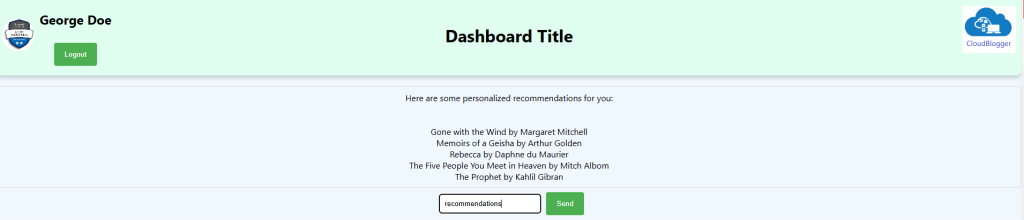
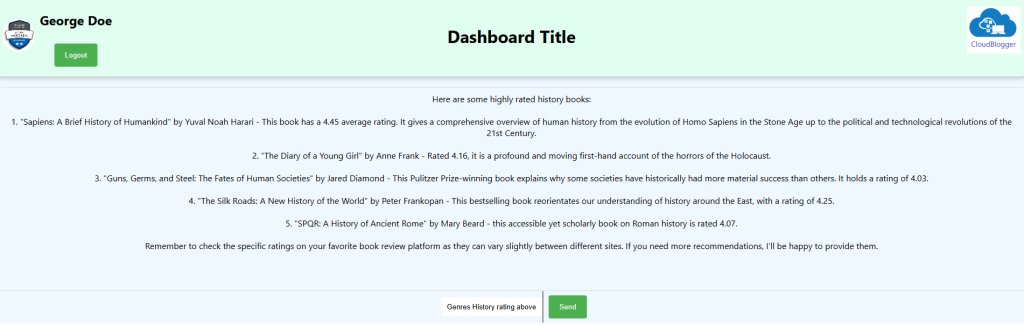
The UI needs some fine tuning, we can add Chat History and you are welcome to do it![Done] Please find the code in GitHub and in case you need help let me know !
Κλείσιμο
We just build our own Web AI Assistant with an enhanced recommendation engine, utilizing a number of Azure and Microsoft Services. It is important to prepare well ahead of such a project, load yourself with patience and be prepared to make mistakes and learn ! I reached 15 Docker Images for the backend to have a basic functionality ! But hey i did it for everyone so you can just grab it and enjoy it, even make it better! Thank you for staying up to this point!
Αναφορές:
Pingback: Microsoft Fabric: Build unique solutions for the Enterprise - CloudBlogger@2024